Broad Clinical Labs (BCL) is a subsidiary of the Broad Institute of MIT and Harvard that provides a range of research and clinical services — including CLIA certified and CAP accredited genomic data generation and advanced genomic analysis — both for the Broad research community and for the rest of the world.
About Us
Broad Clinical Labs (BCL) is a subsidiary of the Broad Institute of MIT and Harvard that provides a range of research and clinical services — including CLIA certified and CAP accredited genomic data generation and advanced genomic analysis — both for the Broad research community and for the rest of the world.
BCL is comprised of 240+ people with expertise in a range of disciplines.
Alliance and project management
Analytics, laboratory information management systems (LIMS), and data visualization
Computational and AI methods and tools development
Data processing, management, and delivery
High throughput lab operations, sample management, robotics, and bioautomation
Molecular methods development, R&D, and product development
Quality and compliance
Rapid technology integration, development, and scaleup
Translational analysis
Variant analysis, clinical interpretation and reporting, and genetic counselling
Work design, visual management, six sigma, and lean manufacturing
Our History
Broad Clinical Labs (BCL) has evolved from the Broad Institute’s Genomics Platform (GP), which has a 30-year track record of delivering on transformative projects in the field of genomics. Throughout our history we have created foundational genomics resources and capabilities for the community and undertaken large-scale disease-based projects that pioneer approaches and advance the understanding of the genomic basis of disease and other traits.
Since the inception of the Human Genome Project in the 1990s, we have played a leadership role in the design, data generation, and methods development in support of major genomic resource projects including:
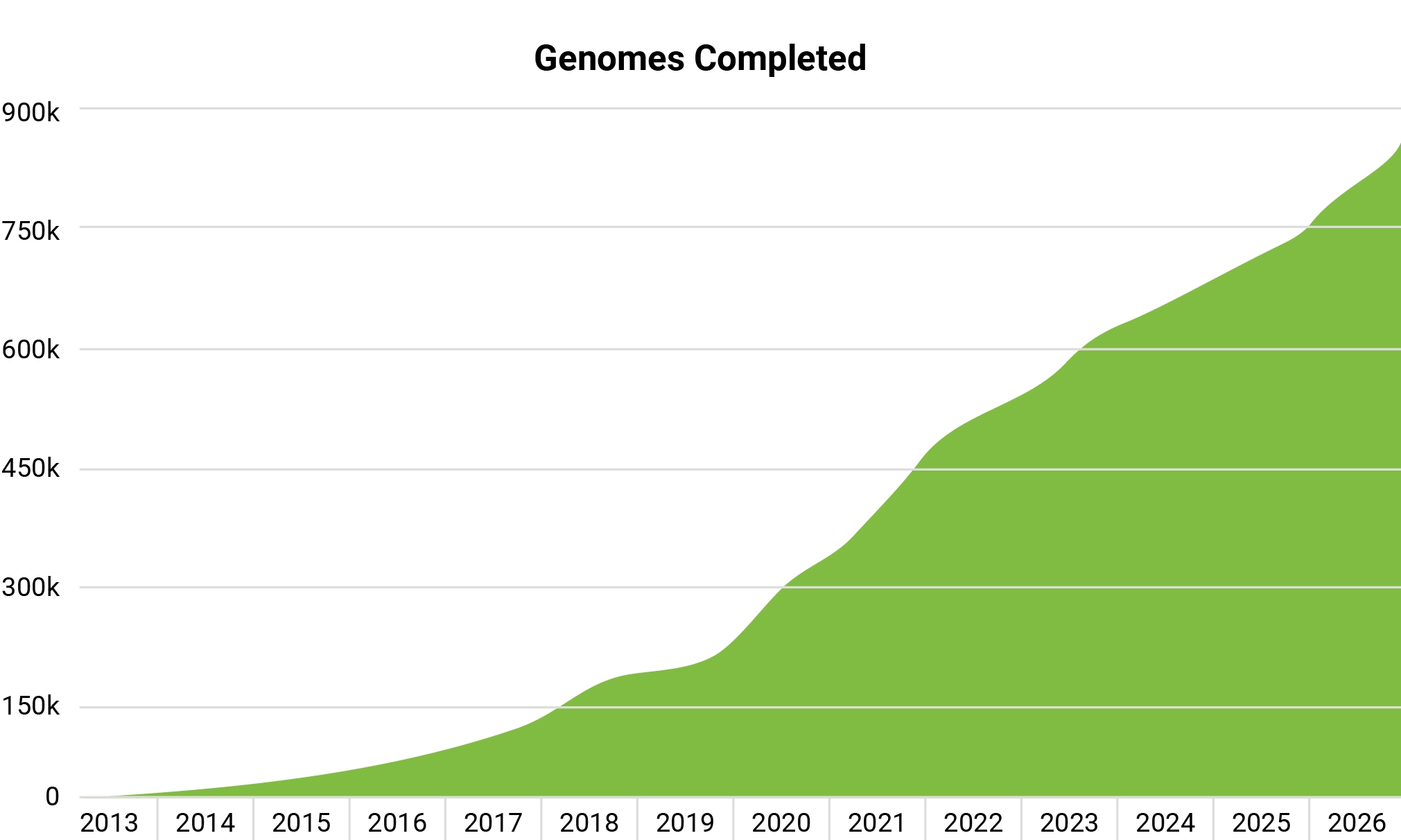
Over the past ten years, we have been the largest producer of human genomic information in the world, and during the SARS-CoV-2 pandemic were one of the largest producers of COVID-19 diagnostic test results in the world. Since 2022, we have routinely generated >2,000 terabases per month of genomic data — a rate equivalent to one whole human whole genome every three minutes. We have processed more than 3 million genomic specimens (including >850k genomes and >1 million exomes) from more than 1,400 groups in more than 50 countries.
Since 2022, we have processed over half a million genomic specimens from around the world , which were processed through workflows including whole genome and whole exome sequencing, RNA sequencing, genotyping, Covid sequencing, and many others including cancer panel sequencing, single cell sequencing, and non-Covid microbial sequencing. The data generated and projects supported by data generation from these specimens are destined to contribute knowledge to a wide array of fields, from rare disease research to population genomics, from cancer clinical trials to understanding cell circuitry.
BCL is located at 27 Blue Sky Drive in Burlington, Massachusetts, in a dedicated 100,000 square foot facility, which has been designed as a production facility, with each of the various functions utilizing specific space to maximize productivity. Our physical lab operation is modular, flexible, and arranged in an order mirroring the workflow, to enable rapid integration of process changes and improvements, and to readily scale as needed. Installed equipment includes hundreds of pieces of sample prep automation, ~1,000 sq. ft. of cold room storage, and a large dual-room walk-in -20°C freezer area for sample storage and retrieval of up to 4 million specimens. Our current sequencer fleet includes 45 Illumina instruments (5 NovaSeq X Plus, 26 NovaSeq 6000, 4 HiSeq 2500, 4 MiSeq, 3 NextSeq 500, 2 NextSeq 2000, and 1 iSeq as well as 10 cBot cluster generation systems), 5 PacBio Revio, 21 PacBio Sequel IIe Units, 1 Oxford Nanopore GridION, 1 Oxford Nanopore PromethION, 3 Element Aviti Instruments, and 2 Ultima Genomics UG100 instruments.
>850,000 whole genomes sequenced to date
Rapid Clinical Dx process development and scale-up during the pandemic
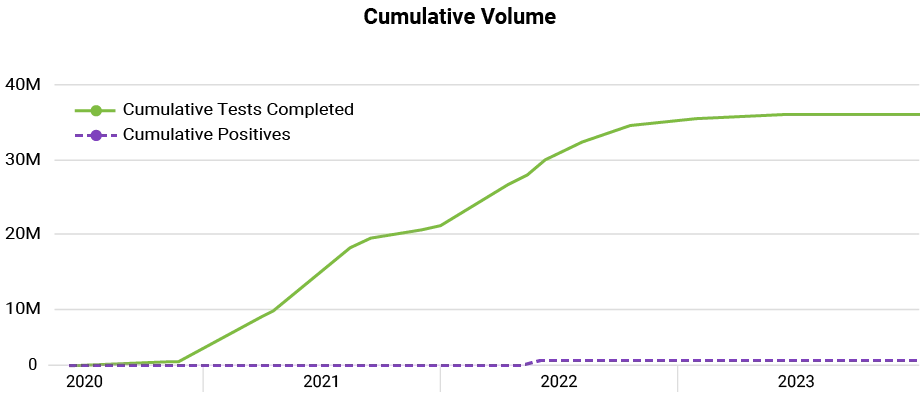
In March 2020 we built and launched a large-scale COVID-19 diagnostic testing service, which has since ceased operations but processed as many as 140,000+ tests per day during the height of the pandemic, and over 37 million tests in its ~3 ⅓ years of operation. Average daily turnaround time from sample receipt to return of results was 10.3 hours. We also built and launched a viral genomic surveillance process with a capacity to pick (from our Covid-19 Dx testing line), sequence, and analyze 10,000 positive samples/week, with results reported to state and federal agencies monitoring variants circulating the population.
Total Tests Completed
37,505,479 since 3/25/2020
Positive Tests
909,690
2% of tests
Inconclusive & Invalid Tests
274,516
0.7% of tests
Working with us
Please browse the website for information on our services to get started or to request more information. If you’re interested in collaborating with us in other ways, or if our services don’t precisely meet your needs, please reach out by clicking “Other Inquiries” below. We are able to develop custom processes depending upon project deliverables, scope, and scale.
Chief of Clinical Strategy and Product Development, Broad Clinical Labs
Sean Hofherr is dual board certified by ABMGG in Clinical Biochemical Genetics and Clinical Molecular Genetics. Sean serves as the Chief of Clinical Strategy and Product Development at Broad Clinical Labs. In this role at BCL, Sean is able to leverage his extensive experience to guide the clinical vision and delivery across the organization. Sean most recently served as the Chief Operating Office at Fabric Genomics, which focuses on the use of AI and Bioinformatics for Clinical Interpretation of whole genome sequencing. Prior to Fabric, Sean was the Chief Scientific Officer and CLIA Director at the commercial reference laboratory, GeneDx.
Sean received his B.S. degree in Microbiology and Cell Sciences from the University of Florida before earning his Ph.D. in Molecular and Human Genetics from Baylor College of Medicine. Sean completed clinical fellowships in Clinical Biochemical Genetics and Clinical Molecular Genetics at the Mayo Clinic.
Danielle Perrin
Chief of Staff, Broad Clinical Labs
As Broad Clinical Labs’ Chief of Staff, Danielle Perrin advises and supports colleagues on the executive leadership team in BCL’s strategic planning and execution. She builds and leads new organizational functions and processes and leads critical projects, as well as driving effective information flow, decision making, and execution throughout the organization. An operations leader with a business, engineering, and biology background and 20+ years of experience in the genomics field, Perrin has a track record of driving operational excellence and building and scaling both physical and business processes. During her career at Broad, which started in 2003 at the tail end of the Human Genome Project, Perrin has led laboratory operations and R&D teams in Broad’s Genomics Platform, as well as fulfilling senior advisory and leadership roles in the Broad Institute’s COO and CFO offices.
Perrin received her B.S. in Biology and M.E. in Biotechnology Engineering from Tufts University and her M.B.A. from the MIT Sloan School of Management.
Tim De Smet
Chief Commercial Officer, Broad Clinical Labs
As Chief Commercial Officer of Broad Clinical Labs, Tim De Smet leads BCL’s business development, alliance management, external project management, and customer support teams. A Broad Institute employee since 2008, De Smet has held leadership roles and managed teams of various sizes in Broad’s Genomics Platform and clinical lab, spanning laboratory operations, finance, and informatics, and has expertise in work design, financial modeling, and high scale laboratory and business operations.
De Smet received his B.S. in Biochemistry and M.B.A. from Northeastern University.
Jim Meldrim
Chief Technology Officer, Broad Clinical Labs
As Chief Technology Officer, Jim Meldrim sets the vision for Broad Clinical Labs’ informatics systems, including the hardware and software used for sample intake and tracking, data production, analysis, and delivery. Having held a variety of laboratory and informatics-focused leadership roles at Broad, spanning R&D and production operations, Meldrim has been a leader and innovator in the generation, management, and analysis of genomic data since 1999, beginning with sequencing data generation for the Human Genome Project.
Meldrim received his B.S. in Biology from Cornell University.
Sheila Dodge
Chief Operating Officer, Broad Clinical Labs
As Chief Operating Officer, Sheila Dodge leads Broad Clinical Labs’ process development and implementation activities, as well as lab operations, financial planning and operations, quality & compliance, and core business processes. A Six Sigma Black Belt with extensive experience in process development and high throughput genomics operations, Dodge is an expert in work design and in collaborating with a range of collaborators, scientists, engineers, and technology partners to rapidly integrate new technologies and operationalize innovations. A member of the Broad Institute since 2001, Dodge is an Institute Scientist and lectures at the MIT Sloan School of Management on operations, dynamic work design, and visual management techniques.
Dodge received her B.A. in biochemistry and molecular biology from Boston University and her master’s degree in biology from Harvard University. She earned her M.B.A. from MIT Sloan School of Management.
Heidi Rehm, Ph.D., FACMG
Chief Medical Officer and Clinical Laboratory Director, Broad Clinical Labs
Heidi Rehm is board-certified by ABMGG in Clinical Molecular Genetics and Genomics and serves as BCL’s Chief Medical Officer and Clinical Laboratory Director. She oversees BCL’s regulatory requirements, leads the clinical team performing genomic interpretation and variant analysis, and guides BCL’s efforts in genomic testing for clinical and research use. She is also an Institute Member of the Broad and co-director of the Medical and Population Genetics Program. Rehm is also the Chief Genomics Officer in the Department of Medicine and Genomic Medicine Unit Director at the Center for Genomic Medicine at Massachusetts General Hospital, working to integrate genomics into medical practice. She is a principal investigator of ClinGen, providing free and publicly accessible resources to support the interpretation of genes and variants. She co-leads both the Broad Center for Mendelian Genomics, focused on discovering novel rare disease genes, and the Matchmaker Exchange, which aids in gene discovery. She is Chair of the Global Alliance for Genomics and Health, a principal investigator of the Broad-LMM-Color All of Us Genome Center, co-leader of the Genome Aggregation Database (gnomAD), and a Board Member and Vice President of Laboratory Genetics for the American College of Medical Genetics and Genomics.
Rehm received her B.A. degree in molecular biology and biochemistry from Middlebury College before earning her M.S. in biomedical science from Harvard Medical School and Ph.D. in genetics from Harvard University. She completed her post-doctoral training with David Corey in neurobiology and a fellowship in clinical molecular genetics at Harvard Medical School.
Niall Lennon, Ph.D.
Chair and Chief Scientific Officer, Broad Clinical Labs
As Chair and Chief Scientific Officer of Broad Clinical Labs, Niall Lennon leads the team and sets the scientific and clinical vision for the organization. Dr. Lennon joined the Broad Institute in 2006 and has since contributed to the development of applications for every major massively parallel sequencing platform across a range of fields. In 2013 Dr. Lennon led the effort to establish a CLIA licensed, CAP-accredited clinical laboratory at the Broad Institute to facilitate return of results to patients and to support clinical trials. More recently, he has led efforts to achieve FDA approval for large-scale genomics projects (NIH’s All of Us Research Program) and for Broad’s own clinical diagnostic for COVID-19 testing operation, which returned 37+ million results to patients. Dr. Lennon is a principal investigator of the eMerge and All of Us projects, an Institute Scientist at Broad, Associate Director of Broad’s Gerstner Center for Cancer Diagnostics, and an adjunct professor of biomedical engineering at Tufts University, where he teaches Molecular Biotechnology.
Dr. Lennon received a Ph.D. in pharmacology from University College Dublin and completed his postdoctoral studies at Harvard Medical School and Massachusetts General Hospital. He holds an executive certificate in management from the MIT Sloan School of Management.